Time series forecasting in Power BI is one of those features that looks deceptively simple on the surface but has serious depth when you need it. Whether you’re predicting sales, inventory needs, or customer demand, Power BI gives you multiple approaches ranging from one-click forecasting to sophisticated custom models using Python and R.
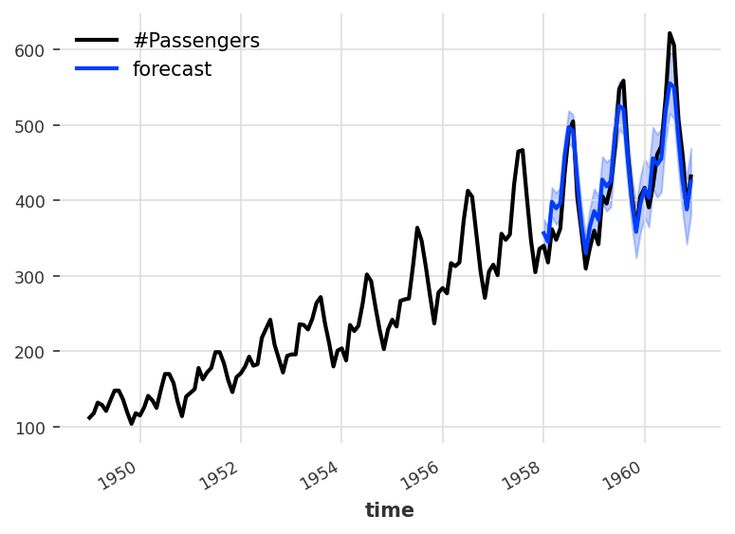
The key is knowing which approach fits your data and business needs. Let’s break down everything from the built-in analytics line to building custom ARIMA models that would make a data scientist proud.
Understanding Time Series Data in Power BI
Before we jump into forecasting methods, let’s get the data structure right. Time series forecasting in Power BI works best when your data follows these principles:
Essential Data Structure:
- Date/time column (properly formatted as Date type)
- Numeric measure to forecast
- Consistent time intervals (daily, weekly, monthly)
- Sufficient historical data (at least 2-3 cycles of your pattern)
Common Data Issues That Break Forecasting:
2024-01-01: 100
2024-01-03: 120 // Missing Jan 2nd
2024-01-08: 110 // Gap of 5 days
2024-01-01: 100
2024-01-02: 120
2024-01-03: 110
Power BI’s forecasting algorithms expect regular intervals. If you have gaps, you’ll need to fill them or aggregate to a consistent level first.
Method 1: Built-in Analytics Line (The Quick Win)
Power BI’s Analytics line is the fastest way to add forecasting to any line chart. Right-click on any line chart, go to Analytics and add a Forecast line. It’s that simple.
What it does under the hood:
- Uses exponential smoothing algorithms
- Automatically detects seasonality
- Provides confidence intervals
- Handles missing values reasonably well
Best for:
- Quick business insights
- Data with clear trends and seasonality
- When you need something fast for presentations
- Non-technical users who want forecasts
Configuration options:
- Forecast length (how many periods ahead)
- Confidence interval (usually 95%)
- Seasonality detection (auto or manual)
Example use case: Monthly sales data with seasonal patterns. Add a forecast line to see next quarter’s expected performance with confidence bands.
The Analytics line works great for standard business scenarios, but it’s a black box. You can’t see the underlying model parameters or customize the algorithm. For more control, you need custom approaches.
Method 2: DAX-Based Forecasting
For more control over your forecasting logic, you can build custom forecasting measures using DAX. This approach gives you transparency and allows for business-specific adjustments.
Simple Moving Average Forecast:
Moving Average Forecast =
VAR CurrentDate = MAX(‘Date'[Date])
VAR PeriodLength = 3 // 3-period moving average
VAR HistoricalValues =
CALCULATETABLE(
VALUES(‘Sales'[Amount]),
DATESBETWEEN(
‘Date'[Date],
CurrentDate – PeriodLength,
CurrentDate
)
)
RETURN
AVERAGEX(HistoricalValues, ‘Sales'[Amount])
Exponential Smoothing with DAX:
Exponential Smoothing Forecast =
VAR Alpha = 0.3 // Smoothing parameter
VAR CurrentDate = MAX(‘Date'[Date])
VAR CurrentValue = SUM(‘Sales'[Amount])
VAR PreviousForecast =
CALCULATE(
[Exponential Smoothing Forecast],
‘Date'[Date] = CurrentDate – 1
)
VAR InitialForecast =
CALCULATE(
AVERAGE(‘Sales'[Amount]),
‘Date'[Date] <= CurrentDate – 30
)
RETURN
IF(
ISBLANK(PreviousForecast),
InitialForecast,
Alpha * CurrentValue + (1 – Alpha) * PreviousForecast
)
Seasonal Adjustment with DAX:
Seasonal Forecast =
VAR CurrentMonth = MONTH(MAX(‘Date'[Date]))
VAR SeasonalIndex =
DIVIDE(
CALCULATE(
AVERAGE(‘Sales'[Amount]),
MONTH(‘Date'[Date]) = CurrentMonth,
‘Date'[Date] < MAX(‘Date'[Date])
),
CALCULATE(
AVERAGE(‘Sales'[Amount]),
‘Date'[Date] < MAX(‘Date'[Date])
)
)
VAR TrendForecast = [Moving Average Forecast]
RETURN
TrendForecast * SeasonalIndex
Pros of DAX forecasting:
- Full transparency and control
- Can incorporate business rules
- Fast execution
- Easy to modify and test
Cons:
- Limited to simple algorithms
- Requires strong DAX skills
- No built-in statistical validation
Method 3: Python Integration for Advanced Forecasting
This is where Power BI really shines for serious time series work. You can use Python’s extensive forecasting libraries directly within Power BI.
Setting up Python forecasting in Power Query:
import pandas as pd
import numpy as np
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_absolute_error, mean_squared_error
import warnings
warnings.filterwarnings(‘ignore’)
# Power BI provides ‘dataset’ DataFrame
dataset[‘date’] = pd.to_datetime(dataset[‘date’])
dataset = dataset.sort_values(‘date’).reset_index(drop=True)
# Create time series
ts = dataset.set_index(‘date’)[‘sales’]
# Ensure regular frequency
ts = ts.asfreq(‘D’, method=’pad’) # Daily frequency, forward fill
# Split data for validation
train_size = int(len(ts) * 0.8)
train, test = ts[:train_size], ts[train_size:]
# Multiple forecasting methods
forecasts = {}
# 1. Exponential Smoothing
es_model = ExponentialSmoothing(
train,
trend=’add’,
seasonal=’add’,
seasonal_periods=7 # Weekly seasonality
).fit()
forecasts[‘exponential_smoothing’] = es_model.forecast(len(test))
# 2. ARIMA Model
# Auto-select parameters (this can be slow with large datasets)
arima_model = ARIMA(train, order=(1, 1, 1)).fit()
forecasts[‘arima’] = arima_model.forecast(len(test))
# 3. Simple seasonal decomposition
from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(train, model=’additive’, period=7)
trend_forecast = np.full(len(test), decomposition.trend.dropna().iloc[-1])
seasonal_forecast = np.tile(decomposition.seasonal[:7], len(test)//7 + 1)[:len(test)]
forecasts[‘seasonal_decomp’] = trend_forecast + seasonal_forecast
# Calculate accuracy metrics
accuracies = {}
for method, forecast in forecasts.items():
mae = mean_absolute_error(test, forecast)
rmse = np.sqrt(mean_squared_error(test, forecast))
accuracies[method] = {‘MAE’: mae, ‘RMSE’: rmse}
# Choose best method (lowest RMSE)
best_method = min(accuracies.items(), key=lambda x: x[1][‘RMSE’])[0]
best_forecast = forecasts[best_method]
# Generate future forecasts
future_periods = 30 # Forecast 30 days ahead
if best_method == ‘exponential_smoothing’:
future_forecast = es_model.forecast(future_periods)
elif best_method == ‘arima’:
future_forecast = arima_model.forecast(future_periods)
else:
# Extend seasonal decomposition
last_trend = decomposition.trend.dropna().iloc[-1]
future_seasonal = np.tile(decomposition.seasonal[:7], future_periods//7 + 1)[:future_periods]
future_forecast = np.full(future_periods, last_trend) + future_seasonal
# Create forecast DataFrame
future_dates = pd.date_range(start=ts.index[-1] + pd.Timedelta(days=1), periods=future_periods, freq=’D’)
forecast_df = pd.DataFrame({
‘date’: future_dates,
‘forecast’: future_forecast,
‘method’: best_method,
‘is_forecast’: True
})
# Combine historical and forecast data
historical_df = dataset.copy()
historical_df[‘forecast’] = historical_df[‘sales’]
historical_df[‘method’] = ‘actual’
historical_df[‘is_forecast’] = False
# Final output
dataset = pd.concat([historical_df, forecast_df], ignore_index=True)
Advanced Python Forecasting with Facebook Prophet:
import pandas as pd
from prophet import Prophet
# Prophet expects specific column names
prophet_data = dataset.rename(columns={‘date’: ‘ds’, ‘sales’: ‘y’})
# Create and fit model
model = Prophet(
daily_seasonality=True,
weekly_seasonality=True,
yearly_seasonality=True,
changepoint_prior_scale=0.05 # Adjust for trend flexibility
)
# Add custom seasonalities if needed
model.add_seasonality(name=’monthly’, period=30.5, fourier_order=5)
model.fit(prophet_data)
# Create future dates
future = model.make_future_dataframe(periods=90, freq=’D’) # 90 days ahead
# Generate forecast
forecast = model.predict(future)
# Extract relevant columns
dataset = forecast[[‘ds’, ‘yhat’, ‘yhat_lower’, ‘yhat_upper’]].rename(columns={
‘ds’: ‘date’,
‘yhat’: ‘forecast’,
‘yhat_lower’: ‘forecast_lower’,
‘yhat_upper’: ‘forecast_upper’
})
# Add forecast flag
dataset[‘is_forecast’] = dataset[‘date’] > prophet_data[‘ds’].max()
Method 4: R Integration for Statistical Forecasting
R’s forecasting capabilities are incredibly sophisticated, especially for complex seasonal patterns and automatic model selection.
Comprehensive R forecasting in Power Query:
library(forecast)
library(tseries)
library(dplyr)
# Convert to time series
dataset$date <- as.Date(dataset$date)
dataset <- dataset %>% arrange(date)
# Create time series object
ts_data <- ts(dataset$sales, frequency = 7) # Weekly seasonality
# Multiple forecasting approaches
forecast_models <- list()
# 1. Auto ARIMA (best practice)
forecast_models$auto_arima <- auto.arima(ts_data, seasonal = TRUE, stepwise = FALSE)
# 2. ETS (Exponential smoothing state space)
forecast_models$ets <- ets(ts_data)
# 3. TBATS (complex seasonality)
forecast_models$tbats <- tbats(ts_data)
# 4. Neural network
forecast_models$nnetar <- nnetar(ts_data)
# Generate forecasts
h <- 30 # Forecast horizon
forecasts <- lapply(forecast_models, function(model) forecast(model, h = h))
# Model selection based on AIC
aic_values <- sapply(forecast_models, AIC)
best_model_name <- names(which.min(aic_values))
best_forecast <- forecasts[[best_model_name]]
# Create forecast dataframe
future_dates <- seq(from = max(dataset$date) + 1, length.out = h, by = “day”)
forecast_df <- data.frame(
date = future_dates,
forecast = as.numeric(best_forecast$mean),
forecast_lower = as.numeric(best_forecast$lower[, “95%”]),
forecast_upper = as.numeric(best_forecast$upper[, “95%”]),
model = best_model_name,
is_forecast = TRUE
)
# Combine with historical data
historical_df <- dataset
historical_df$forecast <- historical_df$sales
historical_df$forecast_lower <- historical_df$sales
historical_df$forecast_upper <- historical_df$sales
historical_df$model <- “actual”
historical_df$is_forecast <- FALSE
# Final dataset
dataset <- rbind(historical_df, forecast_df)
Building a Comprehensive Forecasting Dashboard
Here’s how to structure a professional forecasting dashboard that combines multiple methods:
Key Components:
- Historical vs Forecast Chart – Line chart showing actuals and predictions
- Accuracy Metrics Table – MAE, RMSE, MAPE for model comparison
- Seasonality Decomposition – Trend, seasonal, and residual components
- Forecast Confidence – Upper and lower bounds visualization
- Model Selection Slicer – Switch between different forecasting methods
DAX Measures for Dashboard:
— Forecast Accuracy (MAPE)
Forecast MAPE =
VAR ActualValues =
CALCULATETABLE(
VALUES(‘Data'[Sales]),
‘Data'[Is_Forecast] = FALSE,
‘Data'[Date] >= DATE(2024, 1, 1)
)
VAR ForecastValues =
CALCULATETABLE(
VALUES(‘Data'[Forecast]),
‘Data'[Is_Forecast] = FALSE,
‘Data'[Date] >= DATE(2024, 1, 1)
)
RETURN
AVERAGEX(
ActualValues,
ABS(DIVIDE([Sales] – [Forecast], [Sales]))
) * 100
— Dynamic Forecast Selection
Selected Forecast =
SWITCH(
SELECTEDVALUE(‘Model Selection'[Model]),
“ARIMA”, [ARIMA Forecast],
“Prophet”, [Prophet Forecast],
“Exponential Smoothing”, [ES Forecast],
[Default Forecast]
)
— Forecast vs Actual Variance
Forecast Variance =
IF(
SELECTEDVALUE(‘Data'[Is_Forecast]) = FALSE,
[Sales] – [Selected Forecast],
BLANK()
)
Handling Complex Forecasting Scenarios
Multiple Seasonalities:
# Example: Retail data with daily, weekly, and yearly patterns
from prophet import Prophet
model = Prophet()
model.add_seasonality(name=’daily’, period=1, fourier_order=3)
model.add_seasonality(name=’weekly’, period=7, fourier_order=3)
model.add_seasonality(name=’yearly’, period=365.25, fourier_order=10)
# Add holiday effects
holidays = pd.DataFrame({
‘holiday’: ‘black_friday’,
‘ds’: pd.to_datetime([‘2023-11-24’, ‘2024-11-29’]),
‘lower_window’: -1,
‘upper_window’: 1,
})
model.add_country_holidays(country_name=’US’)
model.holidays = holidays
External Regressors:
# Adding external variables (weather, marketing spend, etc.)
library(forecast)
# Prepare external regressors
xreg_data <- dataset[, c(“temperature”, “marketing_spend”, “competitor_price”)]
xreg_future <- future_data[, c(“temperature”, “marketing_spend”, “competitor_price”)]
# ARIMA with external regressors
arima_model <- auto.arima(ts_data, xreg = as.matrix(xreg_data))
arima_forecast <- forecast(arima_model, xreg = as.matrix(xreg_future), h = 30)
Performance Optimization for Large Datasets
Strategies for handling big time series data:
- Aggregation: Forecast at higher levels (weekly instead of daily)
- Sampling: Use representative subsets for model training
- Incremental Updates: Only retrain models when necessary
- Caching: Store forecasts and update periodically
# Incremental forecasting approach
def incremental_forecast(dataset, last_model_date):
# Only retrain if we have significant new data
new_data_threshold = 30 # days
if (dataset[‘date’].max() – last_model_date).days > new_data_threshold:
# Retrain model with all data
model = train_full_model(dataset)
save_model(model)
else:
# Use existing model with new data points
model = load_saved_model()
return generate_forecast(model, periods=30)
Forecast Validation and Monitoring
Cross-validation for time series:
from sklearn.model_selection import TimeSeriesSplit
def validate_forecast_model(data, model_func, n_splits=5):
tscv = TimeSeriesSplit(n_splits=n_splits)
maes = []
for train_index, test_index in tscv.split(data):
train_data = data.iloc[train_index]
test_data = data.iloc[test_index]
model = model_func(train_data)
forecast = model.predict(len(test_data))
mae = mean_absolute_error(test_data[‘sales’], forecast)
maes.append(mae)
return np.mean(maes), np.std(maes)
Real-time forecast monitoring:
— Forecast Drift Detection
Forecast Drift =
VAR CurrentAccuracy = [Current Period MAPE]
VAR BaselineAccuracy = [Historical Average MAPE]
VAR DriftThreshold = 15 — 15% increase in error
RETURN
IF(
CurrentAccuracy > BaselineAccuracy * (1 + DriftThreshold/100),
“Model Needs Retraining”,
“Model Performing Well”
)
Best Practices and Common Pitfalls
Data Quality Checklist:
- ✅ Consistent time intervals
- ✅ No missing dates in critical periods
- ✅ Outliers identified and handled
- ✅ Sufficient historical data (2+ years for yearly seasonality)
- ✅ External factors documented
Model Selection Guidelines:
- Simple trends: Moving averages or exponential smoothing
- Clear seasonality: ARIMA or ETS models
- Multiple seasonalities: Prophet or TBATS
- External factors: Regression-based models
- Complex patterns: Machine learning approaches
Common Mistakes to Avoid:
- Overfitting: Using too many parameters for the available data
- Ignoring seasonality: Missing obvious patterns in the data
- No validation: Not testing forecasts against held-out data
- Static models: Never updating or retraining models
- Ignoring business context: Forecasting through known disruptions
Putting It All Together: A Complete Forecasting Solution
The most effective approach combines multiple methods:
- Start with Power BI’s built-in forecasting for quick insights
- Use DAX for business-rule adjustments and simple models
- Leverage Python/R for sophisticated algorithms when accuracy matters
- Build ensemble forecasts combining multiple methods
- Monitor and validate continuously to maintain accuracy
Remember, the best forecasting model is the one that provides actionable insights for your business decisions. Sometimes a simple moving average that everyone understands beats a complex neural network that no one trusts.
The key is matching the method to your data characteristics, business requirements, and team capabilities. Power BI gives you the flexibility to start simple and scale up as your forecasting needs evolve.